CSUA Training Results
Praveen
Note: The code had an error, so it was only training one decoder :( So these results are not very significant. See also https://github.com/facebookresearch/music-translation/issues/7 and https://github.com/facebookresearch/music-translation/issues/15
I compared the results of training the Universal Music Translation Network on CSUA to running inference with the provided pre-trained model.
You can see the full log here.
Here are some plots:
Loss
First, I clipped the loss for clarity. Here are some histograms illustrating the need to clip loss:
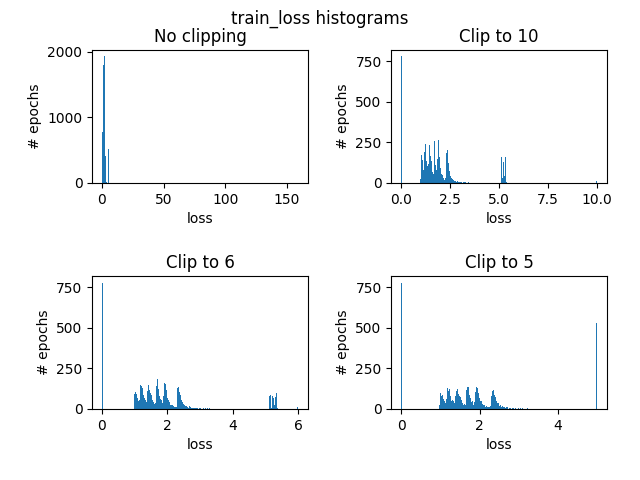
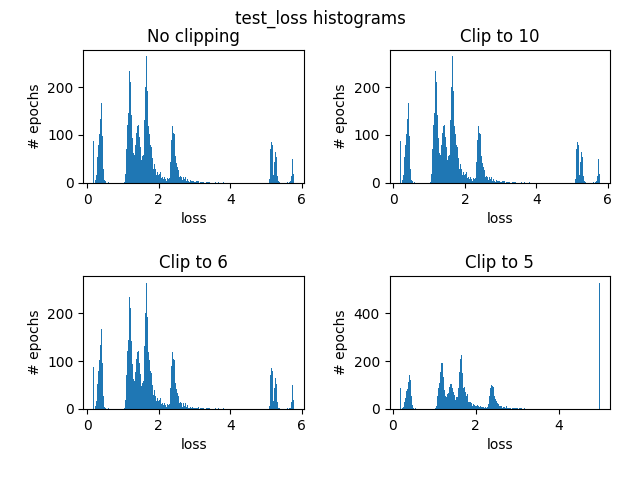
What we can see is that there are a very few epochs that had ridiculously high training loss (150ish) whereas almost all epochs has loss between 0 and 6 for both test and train. So I’ve clipped the loss to that range for the following plots:
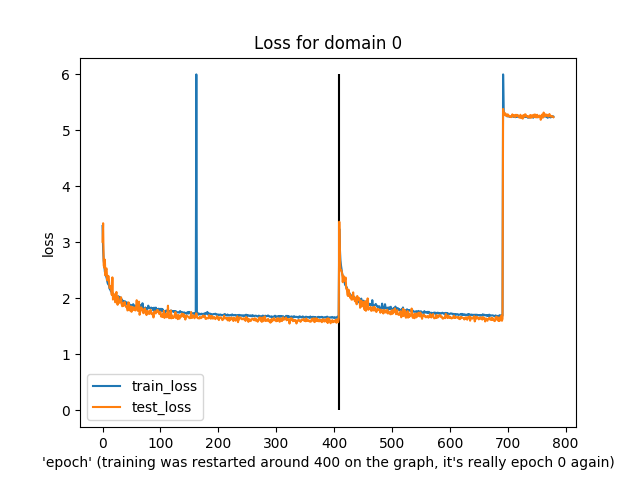
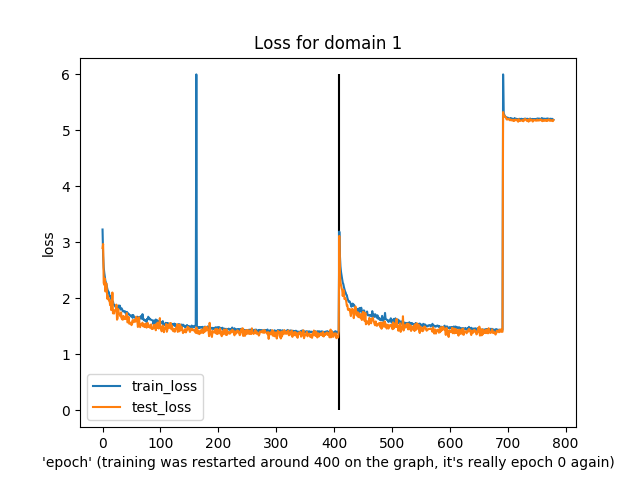
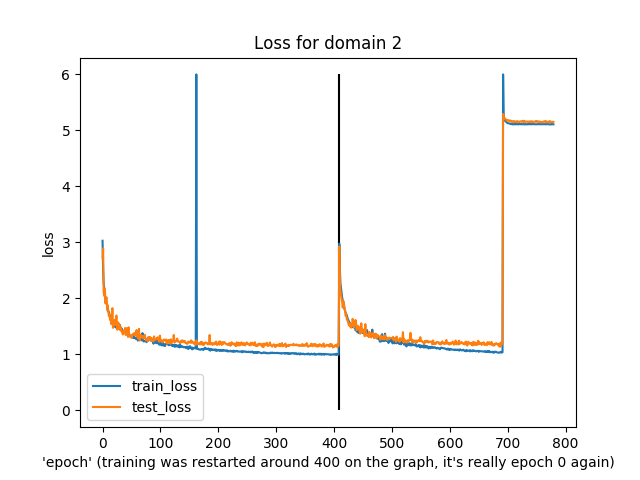
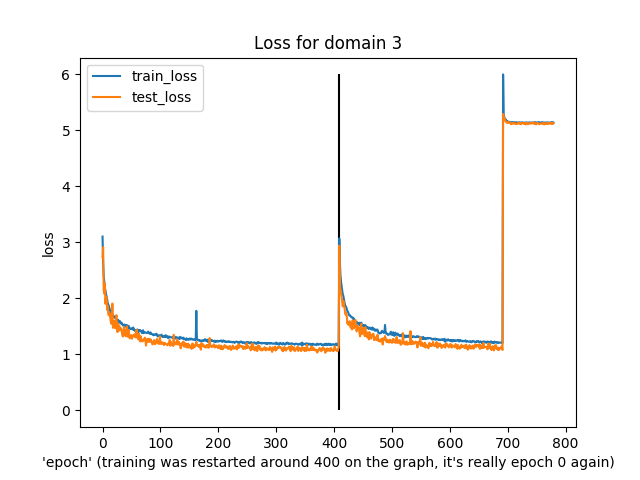
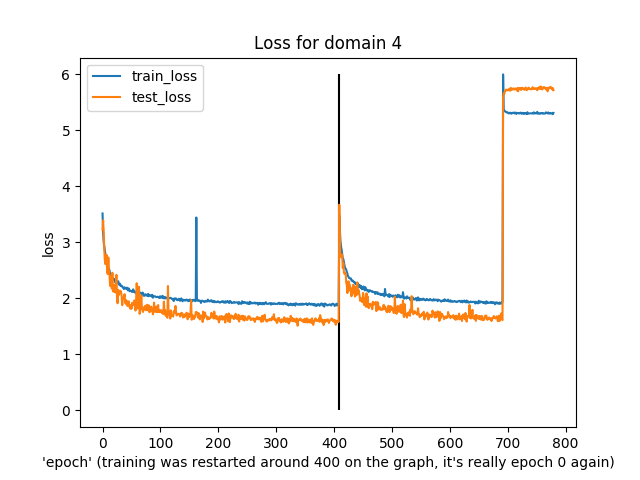
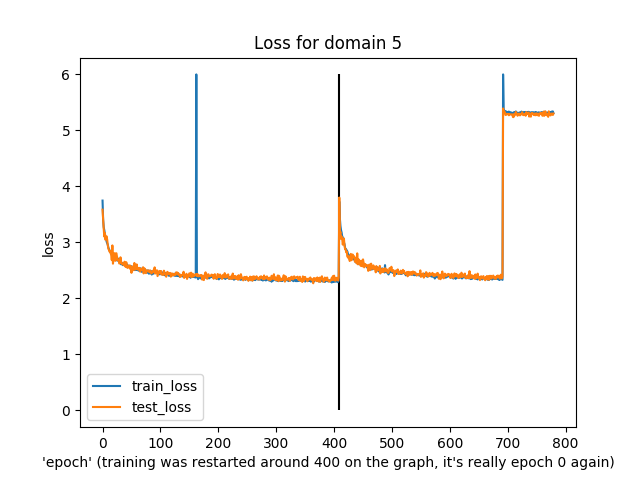
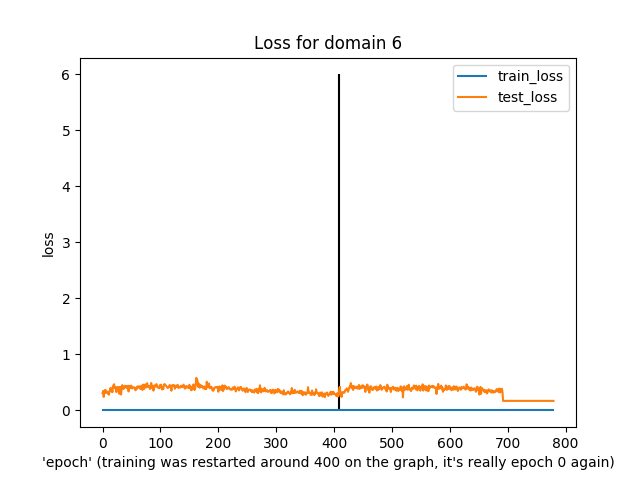
You might notice that this was slightly irregular training. In particular, around the “400” epoch mark the epochs actually reset to 0 because I re-ran the training (and, I guess, didn’t load from a checkpoint…)
Anyway, what’s notable is that both training and test loss did decline over time, apart from domain 6 (I have no idea what was happening there) and a few spikes in train/test loss.
The last run diverged in loss near the end, though, and just generated noise as output.
Audio samples!
Pretrained model
Best model from training on CSUA
The big issue with the trained model seems to be that it’s encoding and decoding domain information. So the result has some piano sound, even though it should be in the cello domain.
Perhaps training for a longer time would help, as long as the model doesn’t diverge.
NOTE: I had to reduce the batch size from 32 to 8 because I wanted to run on only 2 GPUs. This might have increasing the likelihood of the model diverging, as it eventually did.